The Economistがビックマック指数を公開している件について
英国のThe Economistがビックマック指数をオープンデータ化しています.データ分析を練習していると,データが無性に欲しくなる時がありますが,こう言うオープンデータの流れが広まると僕らのデータリテラシーが高まりますね.
記事の中でも,今後公開できるものについてはどんどん公開していく予定であると述べています.
We plan to publish more of our data on GitHub in the coming months—and, where it’s appropriate, the analysis and code behind them as well. We look forward to seeing how our readers use and build upon the data reporting we do. If you have thoughts on the way we’ve released these data, or how we should go about releasing more in the future, please let us know.
データ分析に興味がある人ととして非常にありがたいのが,GitHubではThe Economistがコードを公開しています(当たり前っちゃ当たり前だけど).
例えばこんな感じ:
library('tidyverse')
library('data.table')
big_mac_countries = c('ARG', 'AUS', 'BRA', 'GBR', 'CAN', 'CHL', 'CHN', 'CZE', 'DNK',
'EGY', 'HKG', 'HUN', 'IDN', 'ISR', 'JPN', 'MYS', 'MEX', 'NZL',
'NOR', 'PER', 'PHL', 'POL', 'RUS', 'SAU', 'SGP', 'ZAF', 'KOR',
'SWE', 'CHE', 'TWN', 'THA', 'TUR', 'ARE', 'USA', 'COL', 'CRI',
'PAK', 'LKA', 'UKR', 'URY', 'IND', 'VNM', 'GTM', 'HND', # Venezuela removed
'NIC', 'AZE', 'BHR', 'HRV', 'JOR', 'KWT', 'LBN', 'MDA', 'OMN',
'QAT', 'ROU', 'EUZ')
base_currencies = c('USD', 'EUR', 'GBP', 'JPY', 'CNY')
big_mac_data = fread('./source-data/big-mac-source-data.csv', na.strings = '#N/A',
# sort by date and then by country name, for easy reading;
# index on currency_code for faster joining
key = 'date,name', index = 'currency_code') %>%
# remove lines where the local price is missing
.[!is.na(local_price)]
big_mac_data[, dollar_price := local_price / dollar_ex]
big_mac_index = big_mac_data[
!is.na(dollar_price) & iso_a3 %in% big_mac_countries
,.(date, iso_a3, currency_code, name, local_price, dollar_ex, dollar_price)]
for(currency in base_currencies) {
big_mac_index[
,
(currency) := dollar_price / .SD[currency_code == currency]$dollar_price - 1,
by=date
]
}
big_mac_index[, (base_currencies) := lapply(.SD, round, 3L), .SDcols=base_currencies]
fwrite(big_mac_index, './output-data/big-mac-raw-index.csv')
big_mac_gdp_data = big_mac_data[GDP_dollar > 0]
regression_countries = c('ARG', 'AUS', 'BRA', 'GBR', 'CAN', 'CHL', 'CHN', 'CZE', 'DNK',
'EGY', 'EUZ', 'HKG', 'HUN', 'IDN', 'ISR', 'JPN', 'MYS', 'MEX',
'NZL', 'NOR', 'PER', 'PHL', 'POL', 'RUS', 'SAU', 'SGP', 'ZAF',
'KOR', 'SWE', 'CHE', 'TWN', 'THA', 'TUR', 'USA', 'COL', 'PAK',
'IND', 'AUT', 'BEL', 'NLD', 'FIN', 'FRA', 'DEU', 'IRL', 'ITA',
'PRT', 'ESP', 'GRC', 'EST')
big_mac_gdp_data = big_mac_gdp_data[iso_a3 %in% regression_countries]
big_mac_gdp_data[,adj_price := lm(dollar_price ~ GDP_dollar)$fitted.values, by=date]
big_mac_adj_index = big_mac_gdp_data[
!is.na(dollar_price) & iso_a3 %in% big_mac_countries
,.(date, iso_a3, currency_code, name, local_price, dollar_ex, dollar_price, GDP_dollar, adj_price)]
for(currency in base_currencies) {
big_mac_adj_index[
,
(currency) := (dollar_price / adj_price) /
.SD[currency_code == currency, dollar_price / adj_price] - 1,
by=date
]
}
big_mac_adj_index[, (base_currencies) := lapply(.SD, round, 3L), .SDcols=base_currencies]
fwrite(big_mac_adj_index, './output-data/big-mac-adjusted-index.csv')
big_mac_full_index = merge(big_mac_index, big_mac_adj_index,
by=c('date', 'iso_a3', 'currency_code', 'name', 'local_price', 'dollar_ex', 'dollar_price'),
suffixes=c('_raw', '_adjusted'),
all.x=TRUE
)
fwrite(big_mac_full_index, './output-data/big-mac-full-index.csv')コードがわからなくても,Google スプレッドシートやエクセルを使うと簡単にこんなマッピングもできます.例えば,世界地図に調整済みのビックマック指数を表現(ドル表記)できます.その時間,なんとたったの3秒.
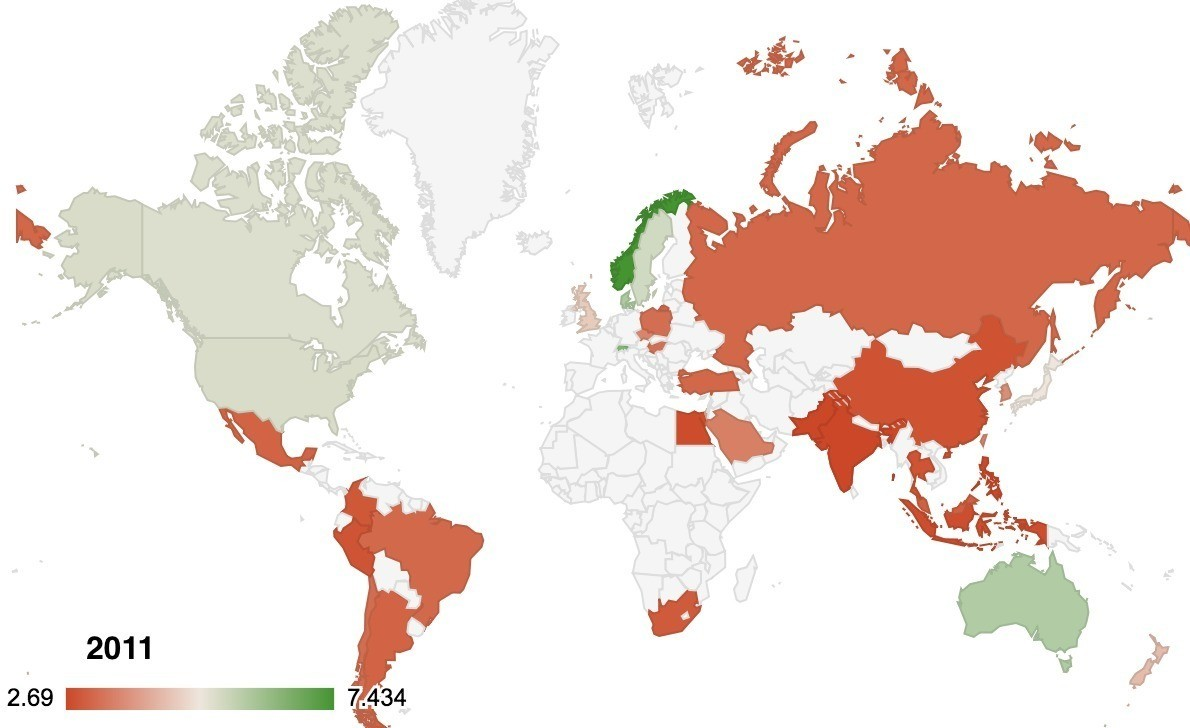
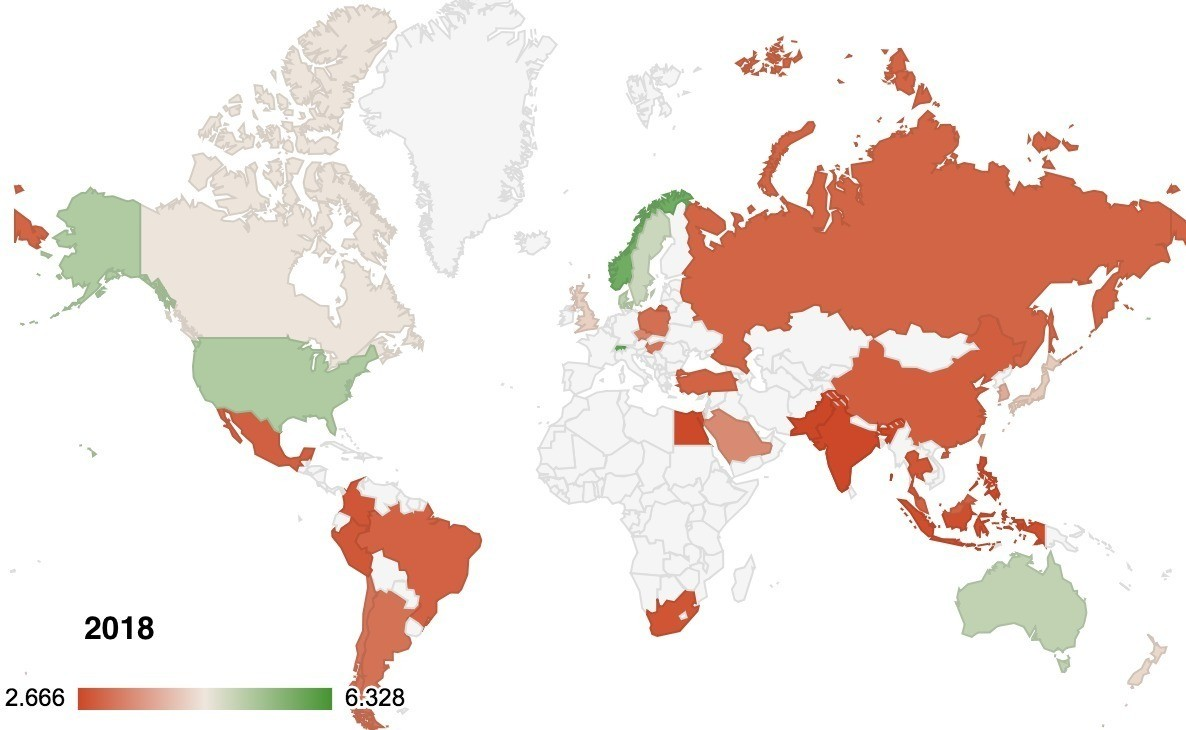
特定の国で,線グラフにしてトレンドラインを入れれば,その国でビックマックが上がっているのか下がっているのかも簡単に確認できます.例えば中国だと:
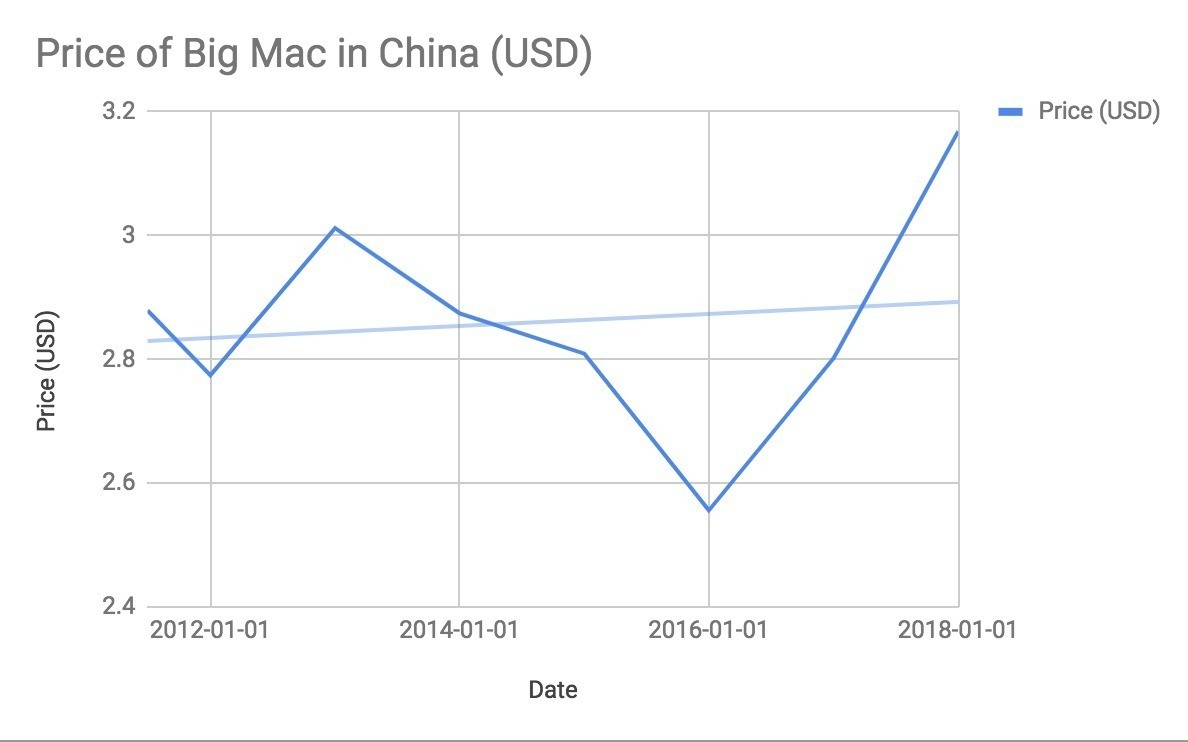
上がっているっぽいですね.友達の中国人に聞いてみたら実感とあっているようです.
誰でもデータリテラシーが求められる時代です.簡単なことでも自分なりにデータをいじって遊びましょう.